evSrc: Evolutionary couplings between files reveal poor design choices in software architecture
Given a software code repository together with all commit history, can you spot potentially problematic parts of the software? This is the question I have been thinking about when I have some extra time left from other projects. As a pet-project, I recently created a proof-of-concept pipeline to show that the answer to this question seems to be yes.
I was thinking about writing up a small application paper for this project, but I am really terrible at reading papers from the Computer Science field, let alone writing them. I also realize that I barely have the time to pursue this project any further, so instead of turning it into a dead project, I decided to write a blog post about the current state of it.
evSrc, or EVolutionary SouRCe, project came into being while I was talking to Richard about the details of maximum entropy-based inference of pairwise interactions from large-scale data sets. In case you missed it, there have been really exciting developments in the Structural Biology field, where it has been shown that using this method and taking advantage of publicly available sequencing information, you can fold proteins and you can even find structures of complexes when you have enough sequences for protein(s). You can learn more about these projects from the EVFold website, but the main pipeline looks something like this:

Basically, given information about pairs of entities, there is a nice way to get rid of a lot of transitive interactions between pairs to get a useful set of correlations between entities, so called couplings. There are many places where you can apply this method, but the couplings you get out of this system should represent something meaningful. Otherwise, what you are doing is simply applying a method in an irrelevant manner. For example, in protein world, the evolutionary couplings between residiues represent functional or structural constraints on those entities. The tricky part is to find data sets where this method might provide you with meaningful results.
I have known about this method for quite some time, but didn’t have a data set to apply it to. This is, of course, until recently when I had an epiphany about software systems. While I was browsing the history of commits for a project of mine, I realized that it holds a great deal of information about the software itself.
For those who are not familiar with Version Contol Systems, I strongly suggest you get yourself familiar with them. In a nut-shell, these systems provides you the means to track changes you make to your source code and to version them properly. So when you look at the history of changes for a particular software project, you see something like this:
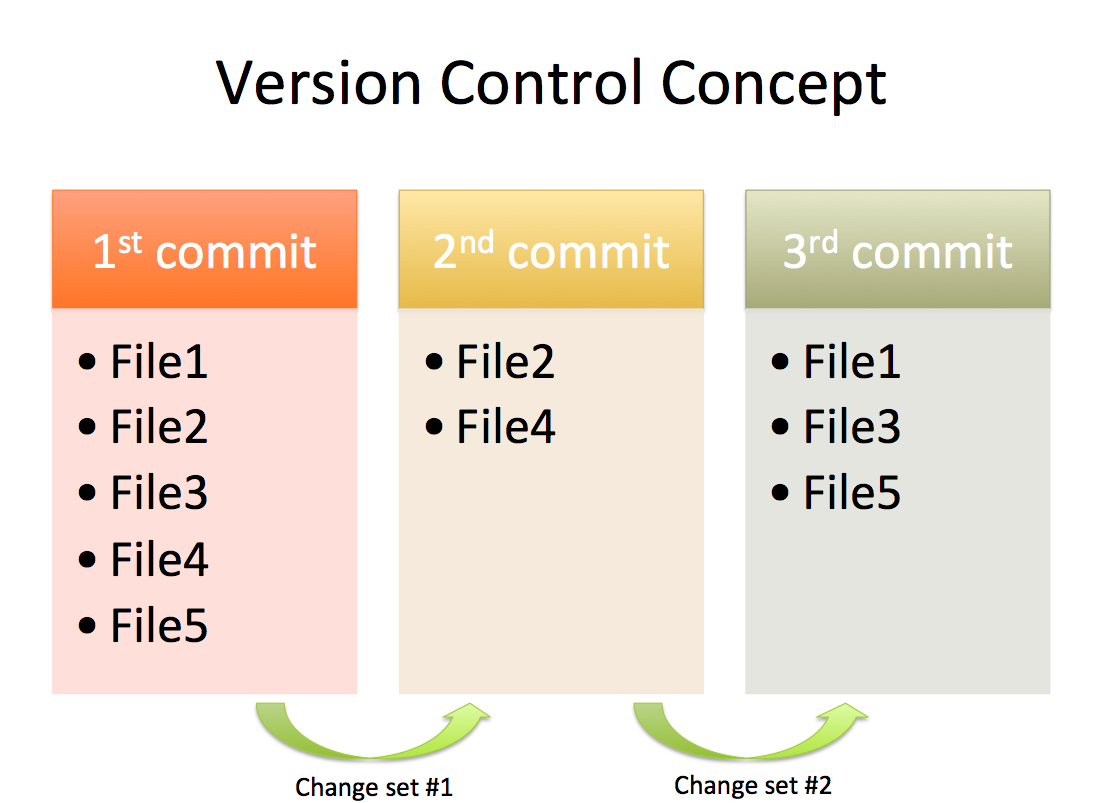
This is, of course, an over-simplification, but the idea here is that you can take this information and create a matrix where you can mark (with 1) in which revision a particular file has changed. And when you do this, you essentially get something similar to a sequence alignment:
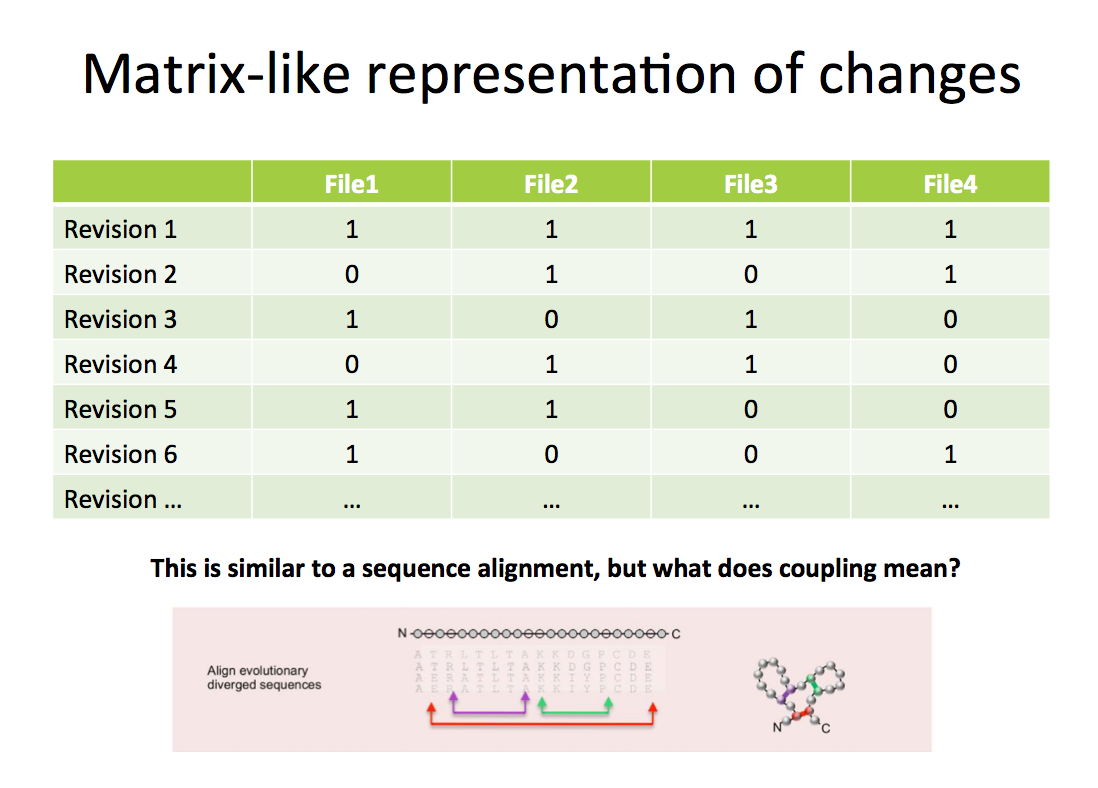
Which is great, because you can use this piece information for inferring evolutionary coupled files in your software. Once the data is in correct format, the inference can easily be done using one of de facto R packages, e.g. corpcor. But what does it mean for source files to be coupled in a software evolution?

Turns out that there is a huge body of literature on this, but for those are curious, here is a way to learn more about this on Google Scholar: software evolution co-change. In short, file couplings are often attributed to bad software design and represent pieces of code that are either duplicated at some point in the history or are not modular. If so, then:
To test this idea, I built this really simple pipeline as a proof of concept:
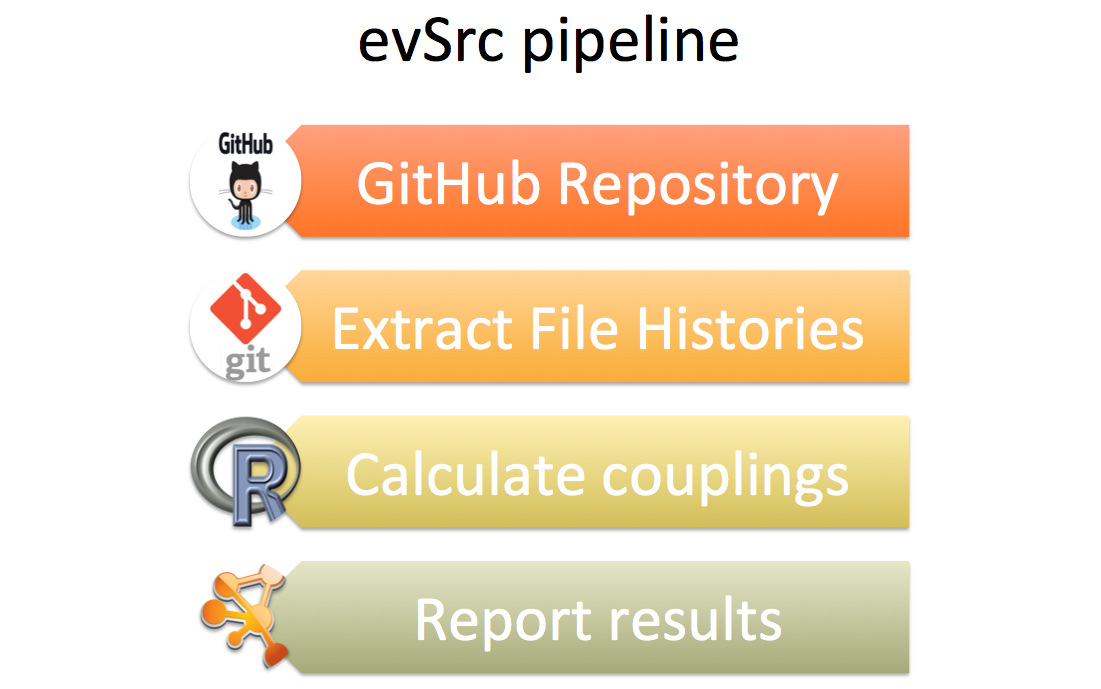
This whole pipeline might seem like a big deal, but it is actually a few lines of code that you can find here on GitHub: armish/evsrc. It basically:
- clones a repository from GitHub into a local folder;
- extracts information about changed files in each revision;
- passes this information to an R-script that infers the couplings;
- visualizes and outputs all the couplings with different specificity.
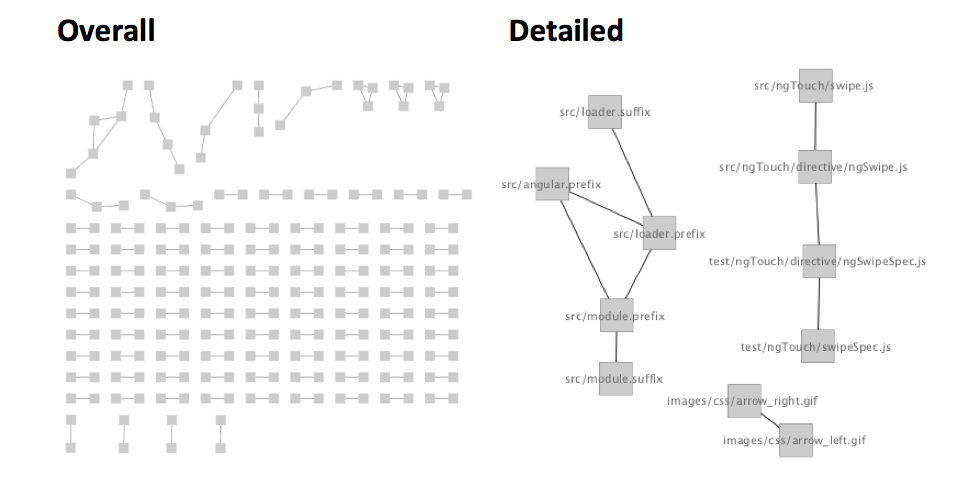
People, of course, have been fancying with this idea for a long time, but as far as I can tell nobody has approached this problem from this perspective. To see if the inference step makes sense and whether it produces reasonable results, I ran this pipeline first on Angular.js:
and then on iPython:
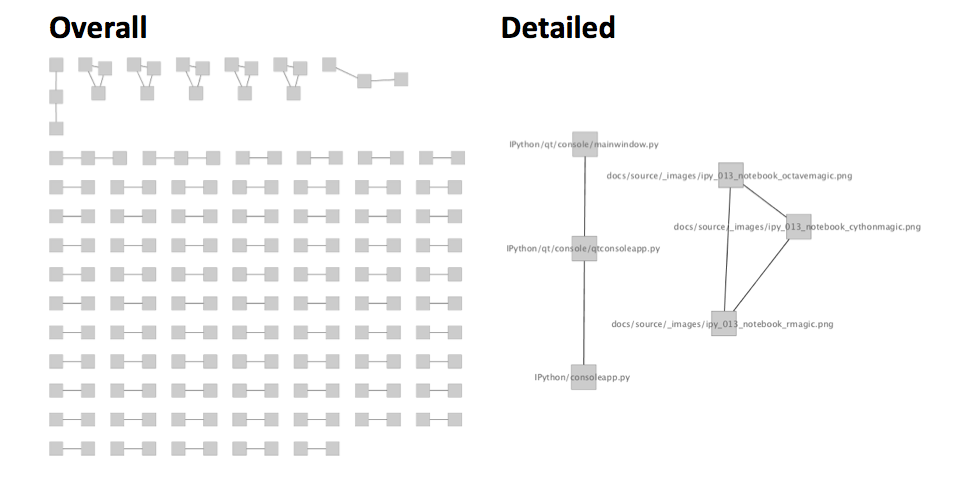
I did this because I knew that both pieces of software are well-maintained and well-designed; so the pairs I get back, if any, should be easier to interpret. In Angular.js, the approach revealed cute couplings, for example a coupling between left arrow image and right arrow image. This makes sense, since every time one of them gets updated, the other one should also be taken care of. In many frameworks, I saw people resolving this kind of issues simply by combining these two into a single sprite sheet.
{kind=link}
{kind=link}
It also turns out that in both pieces of software, a majority of the couplings are attributable to Test Driven Design, where a source file is coupled to its test. So these are apparently false-positives I should take care of in the next version of the pipeline. Beside these, I also get a handful of suspicous couplings that seem to be due bad design, but they require another round of investigation before saying something concerete about them.
In summary, infering evolutionary couplings seems to work fine in software development and it seems to provide interesting information about the design of the software. But to turn this evSrc project into a useful tool, I first need to:
- find examples of badly-designed software projects
- handle exceptional couplings due to good design (e.g. TDD)
- improve the scripts so people can run it more easily
- turn this into a web-based tool where people can simply submit jobs and get interactive networks out of it
- think about ways to integrate this with Integrated Development Environments
- …
I might or might not be able to get to these items in the near future, but at this point, any feedback is more than welcome. Know papers, tools, approaches similar to this? Or want to help me finalize this? Then do let me know :)